new/delete와 사용하지 않는 이유?
- 기능의 과도한 범용성
- 메모리 할당 너머의 hidden behavior 수행
- 불충분한 기능
Memory Managerment의 필요성
- 메모리 사용 및 관리에 용이
- 디버깅과 에러 체킹에 확장성 부여
- 자체 어플리케이션에 맞는 메모리 관리
Memory Manager란?

- 메모리를 하나의 청크로 선 할당
- 이를 다시 여러 블록으로 나눔
- freelist - 나누어진 블럭으로 이루어진 링크리스트
- 할당 시, 사용자는 하나 이상의 메모리에 엑세스를 얻음
- 메모리 블럭에 대한 포인터
- 이 블럭은 사용 중으로 마킹
- 반환 시, 유저가 메모리 매니저에게 직접 반환
Custom Memory Allocator의 요소
- 사용 난이드
- 포인터보다는 핸들
- 프론트 엔드 유저들에게도 용이한 복잡도
- Garbage Collection과 Memory Coalescing
- Garbage Collection: 프로그램이 동적으로 할당했던 메모리 영역 중에서 필요없게 된 영역을 해제
- Memory Coalescing: 단편화로 인해 분산된 메모리공간들을 인접해 있는 것끼리 통합시켜 큰 메모리 공간으로 합치는 기법
- 퍼포먼스
- 속도와 일관성
- 메모리 할당/반환의 규칙화
- 주소 참조의 지역성
- Overhead
- 첫 할당 시 거대한 메모리 오버헤드 발생
- 메모리 블럭 당 사이즈
- 디버깅을 위한 메모리가 추가적으로 필요
- 디버깅
- Memory Leak 체크
- Memory Corruption 체크
- Block들을 특정 값으로 초기화
- 메모리 사용 패턴과 수치화 가능
- 스파이크 지점을 탐색
- 한 메모리 블럭의 평균 라이프 사이클
자동 메모리 관리
- 일반적으로 Garbage Collector라 불림
- 이 경우 메모리는 프로그래머에 의해 반환되지 않음
- GB가 접근 불가능한 메모리를 스캐닝
- 궁극적인 목표는 사용자가 메모리 관리로부터 해방하는 것
- 프로그램 메모리 단계까지 접근할 수 있어야 하므로 구현은 쉽지 않음

- 메모리 관리에 있어 가장 큰 문제
- 파편화로 인해 가용 가능한 메모리 범위를 벗어나는 경우가 많음
Stack Allocator
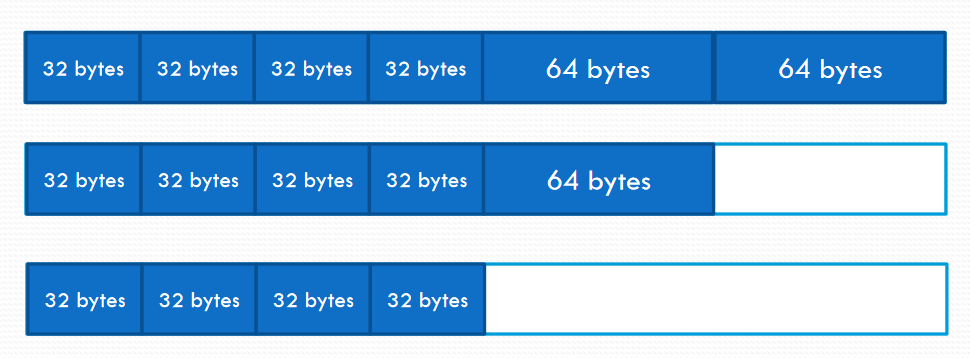
- 파편화를 완전히 막음
- 마지막으로 할당된 메모리를 가장 먼저 free
Fixed Sized Blocks - Pools
- 이 역시 파편화를 완전히 막음
- 범용성에서 어긋남
- 다양한 사이즈의 Pool을 이용할 수는 있음
- 그러나 필요 이상 사이즈의 메모리가 할당되는 경우가 발생
First Fit
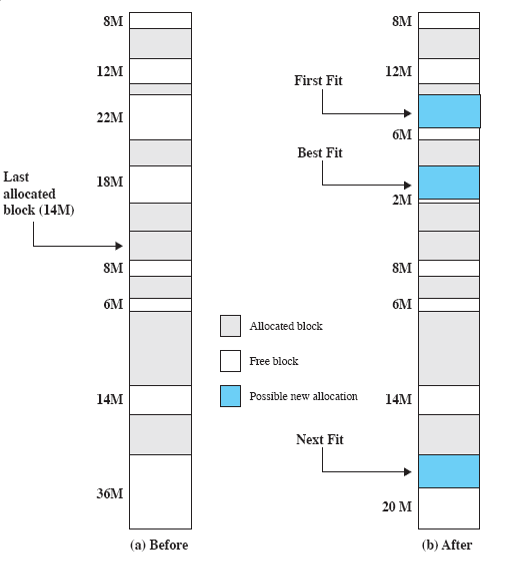
- 시작 지점부터 출발해 가용 가능한 첫 block을 찾으면 그냥 할당
Next Fit
- 마지막으로 사용한 block부터 탐색 시작
- roving pointer를 사용해 pointer가 chunk의 끝에 이르면 처음으로 돌아옴
Best Fit
- 가용 가능한 block 중 가장 작은 사이즈의 block을 사용
- 실용적이지는 않다고 함
Segregated Fit
- 여러 사이즈의 Fixed Sized Blocks, 즉 Pool을 가짐
- 가용 가능한 최소 사이즈의 Pool을 선택
Binary Buddy System
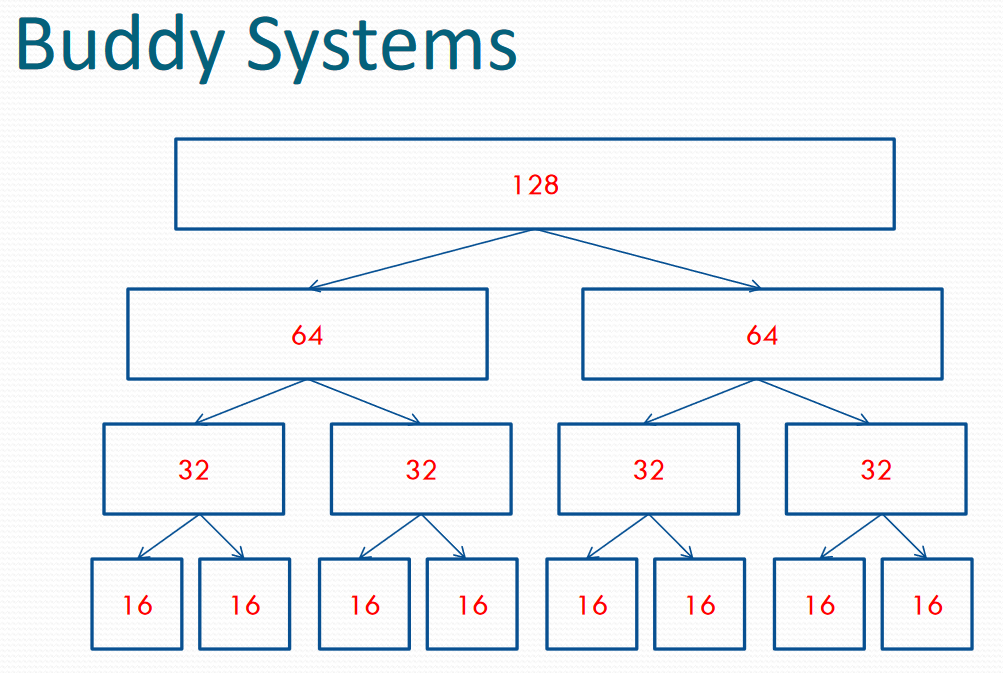
- 바이너리 트리 구조로 메모리 관리
- Block의 사이즈는 트리 레벨과 연관
- 같은 크기의 다른 block을 buddy
- 큰 Block이 필요한 경우, buddy와 merge되어 사용
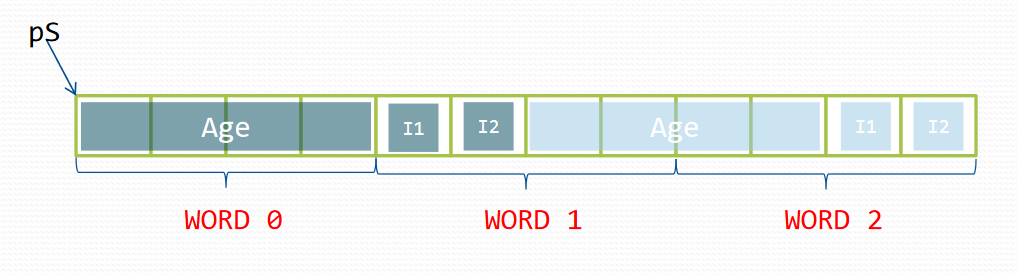
Word
- 하드웨어 또는 프로세서에 의해 제어되는, 고정 크기의 데이터 처리 안뒤
- 꼭 byte일 필요는 없다
- 하드웨어는 한번에 하나의 word에 대한 작업만 수행
- 한 Word 보다 더 큰 메모리 접근이 필요한 경우?
// 예시
struct Student1
{
int Age; // 4 bytes
char Initial_1; // 1 byte
char Initial_2; // 1 byte
};
Student1 * pS = new Student1[2];
| Instruction |
Number of Operation |
| pS[0].Age |
1 |
| pS[0].I1 |
1 |
| pS[1].Age |
2 |
- 위 케이스에서 pS[1].Age는 두번의 작업이 수행되어야만 접근 가능
// 다른 예시
struct Student1
{
char Initial_1; // 1 byte
int Age; // 4 bytes
char Initial_2; // 1 byte
};

| Instruction |
Number of Operation |
| pS[0].Age |
2 |
| pS[0].I1 |
1 |
| pS[0].I2 |
1 |
| pS[1].Age |
2 |
Alignment
- 데이터를 메모리 주소에 맞게 조정하는 것
- Padding
- 사용하지 않는 byte를 추가적으로 할당하는 것
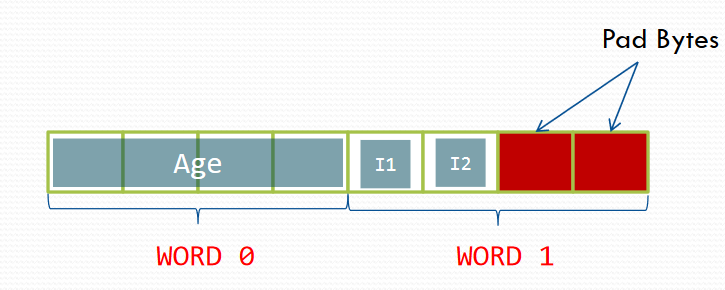
struct Student1
{
int Age; // 4 bytes
char Initial_1; // 1 byte
char Initial_2; // 1 byte
};
// size of Student1 = 8
cout << "size of Student1 = " << sizeof(Student1) << endl;
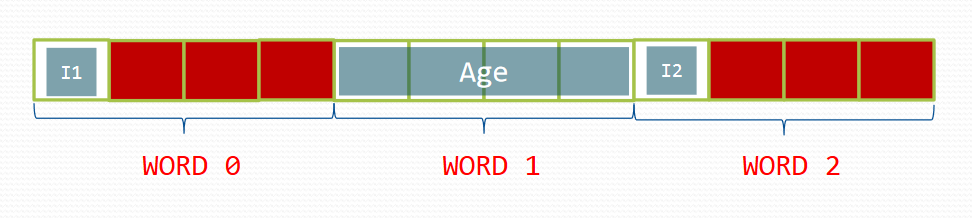
struct Student2
{
char Initial_1; // 1 byte
int Age; // 4 bytes
char Initial_2; // 1 byte
};
// size of Student1 = 12
cout << "size of Student2 = " << sizeof(Student2) << endl;
출처