Cache
캐시 Cache
- CPU가 빠른 속도가 데이터를 주고 받을 수 있도록 도와주는 메모리
- Locality of Reference 원리에 따라 메모리 저장소의 데이터를 미리 가져와 보관
캐시가 빠른 이유
- 참조 지역성의 원리
- 자주 사용하는 데이터를 우선적으로 저장
- 유효 비트와 태그 필드를 이용한 메모리 접근
- 시간 복잡도 O(1)에 수렴
참조 지역성 Locality of Reference의 원리
- 시간 지역성
- 최근에 접근한 데이터에 다시 접근할 가능성이 높다
- ex 1) 루프는 동일한 명령을 반복
- ex 2) 함수 호출 및 반환은 스택 메모리에 반복적인 엑세스가 발생
- 공간 지역성
- 접근한 데이터에 가까운 주소에 접근할 가능성이 높다
- 배열을 처리할 때 등 순차적인 방식으로 메모리에 접근한다
캐시의 구조
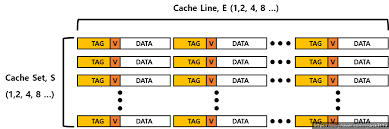
- 캐시 메모리는 S개의 Cache Set으로 구성
- 각 Set은 E개의 Cache Entry를 가지고 있는 캐시 라인으로 구성
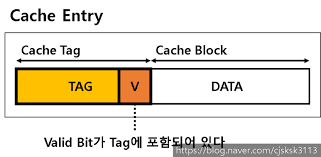
캐시 블록 Cache Block
- 케시 메모리의 데이터 그룹 단위
- 데이터를 가지고 있다
캐시 태그 Cache Tag
- 캐리 블록 고유 식별값
- CPU는 태그 값을 통해 캐시 블록에 접근한다
- 캐시 블록에 올바른 데이터가 저장되어 있는지 Valid bit로 확인
- 비어있거나 비정상적인 값을 가지고 있으면 유효비트는 0으로 set 되어 유효한 블록이 없다고 알려준다
캐시 오버헤드 예시
- 캐시 비트는 캐시 메모리 크기에서 포함되어 있지 않는 오버헤드다
- 태그 오버헤드가 증가할수록 데이터 엑스사에 대한 레이턴시가 증가한다
- 이를 줄이기 위해 CPU는 태그를 확인하는 과정과 데이터에 접근하는 과정을 동시에 수행한다
- 32KB 캐시가 있다고 가정
- 캐시 블록 크기는 32 바이트
- 태그 필드로 17비트 + 유효 비트 1비트 = 캐시 태그 18 비트
- 32KB는 = 32바이트 x 1024개
- 18 비트 x 1024 = 18Kb (키로비트) -> 2.25 KB(키로바이트)
- 32KB의 캐시 메모리는 실제로 34.25KB의 크기다
캐시 활용도를 높이려면?
- 캐시 메모리를 재사용하면 된다
- 하나의 프로그램이 메모리 섹션을 재사용하면 캐시 메모리의 활용도가 올라간다
- 런타임 동안 캐시로 가져오는 동적 메모리의 크기와 횟수를 줄여야 한다
캐시 메모리 관리 방법
- OS가 페이지Page라는 단위로 자주 사용하는 부분과 아닌 부분을 나눠 관리
- Pre-fetch라는 기능을 활용
- 하부 단계의 메모리에서 데이터나 명령을 미리 불러오는 것(?)
- 메모리 레이턴시를 줄이고 하드웨어의 성능을 쥐어짜낸다
- data prefetch 혹은 instruction prefetch
메모리 조각화
함수 기반 조각화
- 부모 함수가 자식 함수를 호출하는 경우, 결함이 존재한다
- 자식 함수의 코드가 캐시에 존재하지 않는 경우 Cache Miss 발생
- 프로세서가 중지한다
- 흐름 변경 Change Of Flow가 발생하면, 파이프라인을 Flush 하면서 사이클에 결함이 발생한다
- Flush
- 기존에 사용하던 버퍼를 비워버리는 것
- 흐름을 변경하면서 버퍼에 저장되어 있던 내용을 비우는 것
코드 기반 조각화
- 함수에는 코너 케이스를 다루는 코드가 포함되어 있다
- 캐시로 읽어들이지만 그 사용률이 감소한다
최적화를 위한 가이드라인
Runtime code와 (Initialization / Corner-Case code) 구분
- 런타임 코드는 알고리즘을 실행할 때마다 실행될 수 있는 중요한 코드만 포함
- 런타임 코드에서 코너 케이스 코드를 제거하면 동적 메모리 공간을 최소화할 수 있다.
Code Positioning + Linker Optimization
- 함수를 임의의 순서로 링크하면 안된다
- 알고리즘의 실시간 함수 호출 흐름을 고려해야 한다
- 코드 및 함수의 선형화
코드를 최적화하는 방법
코드 파티셔닝 Code Partitioning
- 코드를 재구성해 코드 기반의 조각화를 줄임
void foo()
{
if (condition)
{
// large code block 1
}
else
{
// large code block 2
}
// ...
return value;
}
- 위의 코드는 large number code 1, 2 중의 하나를 작동시킨다
- 1, 2중 1만 더 높은 확률로 실행된다면 동적 메모리 크기가 불필요하게 커져 캐시 활용도가 낮아진다
void foo()
{
if (condition)
{
// large code block 1
}
else
{
LargeCode2();
// large code block 2
}
// ...
return value;
}
- 위의 경우에는 자체 지역함수를 콜한다
- 함수의 코드는 메모리의 다른 곳에 위치하기 때문에 공간 지역성이 강제되지 않는다
- 캐시에 코너 케이스 코드까지 담지 않는다
- 캐시 사용률이 높아진다
- Switch 문에도 동일하게 적용할 수 있다
- 함수의 코드는 메모리의 다른 곳에 위치하기 때문에 공간 지역성이 강제되지 않는다
- 많은 케이스가 있다면, 어떤 케이스가 자주 실행되는지 확인해서 자주 실행되지 않는 케이스는 다른 함수를 호출한다
인라이닝 Inlining
- 함수 기반의 메모리 조각화를 줄이는 데 유용
- 함수 안에 다른 함수를 넣어 Change of Flow를 줄이고 선형적으로 만듦
- (code partitioning의 2번째 예시와 무슨 차이?)
- inlining이라면서 함수 호출을 함수의 실제 본문으로 대체하는 건데 ‘함수안에 함수를 넣어’?
- Flush를 줄임으로써 Cache Miss를 방지
- 함수 안에 다른 함수를 넣어 Change of Flow를 줄이고 선형적으로 만듦
- 다음의 변수를 고려할 것
- 함수의 크기
- 함수 호출 빈도
- 코너 케이스인지 아닌지
- 과도한 인라이닝은 오히려 속도를 감소
정렬 Alignment
- 캐시의 유효 메모리 크기를 캐시 라인 1개 미만으로 정렬
- 캐시 라인 바운더리 Cache Line Boundary